最近有一個想法需要收集一些粉絲專頁公開貼文資料,上網查了一下有現成的code!用了發現有些問題,還有我要補抓的東西,想想改寫的code也分享出來。簡單來說呢,主體是用selenium(自動化測試工具)以一個webdriver瀏覽器假裝是真人在看,然後用BeautifulSoup(漂亮湯)html tag解析工具,找到要存的資料。

先說為什麼不用facebook graph api抓取?因為現在連公開內容抓取也需要送審應用程式(上圖),一直還沒搞懂/去走一遍流程(抓取自己粉絲頁的數據從2017年開始每天跑都還活著,也多了點偷懶的理由…)

在一開始提過了,這次的重點是前三項。selenium、webdriver、BeautifulSoup。
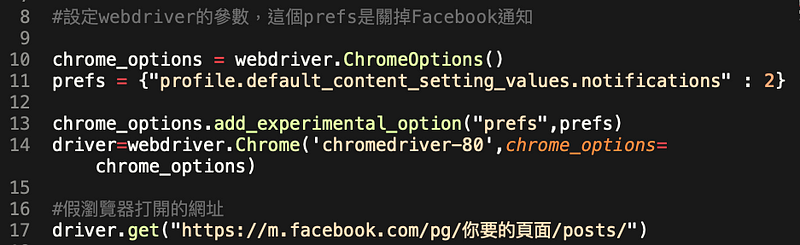
driver這個地方,在開始前需要去下載一個真的webdriver回來,並且要跟目前使用的瀏覽器是相同版本,例如,你要模擬Chrome的使用狀況,就要找Chrome相同版本。
Chrome Webdriver下載:上網Google吧。我下載後放在專案的資料夾裡,以指定路徑的方式打開,加到環境變數也是一種方法。
如果要把程式部署到雲端主機就有另外的設定方法,我有部署到Heroku過,也是東找範例西找解方做出來,下次再整理出來。
這段執行完,瀏覽器就會打開了,如果要手動以帳號密碼登入也是可以的。這裡輸入的是m.facebook.com的版本喔!
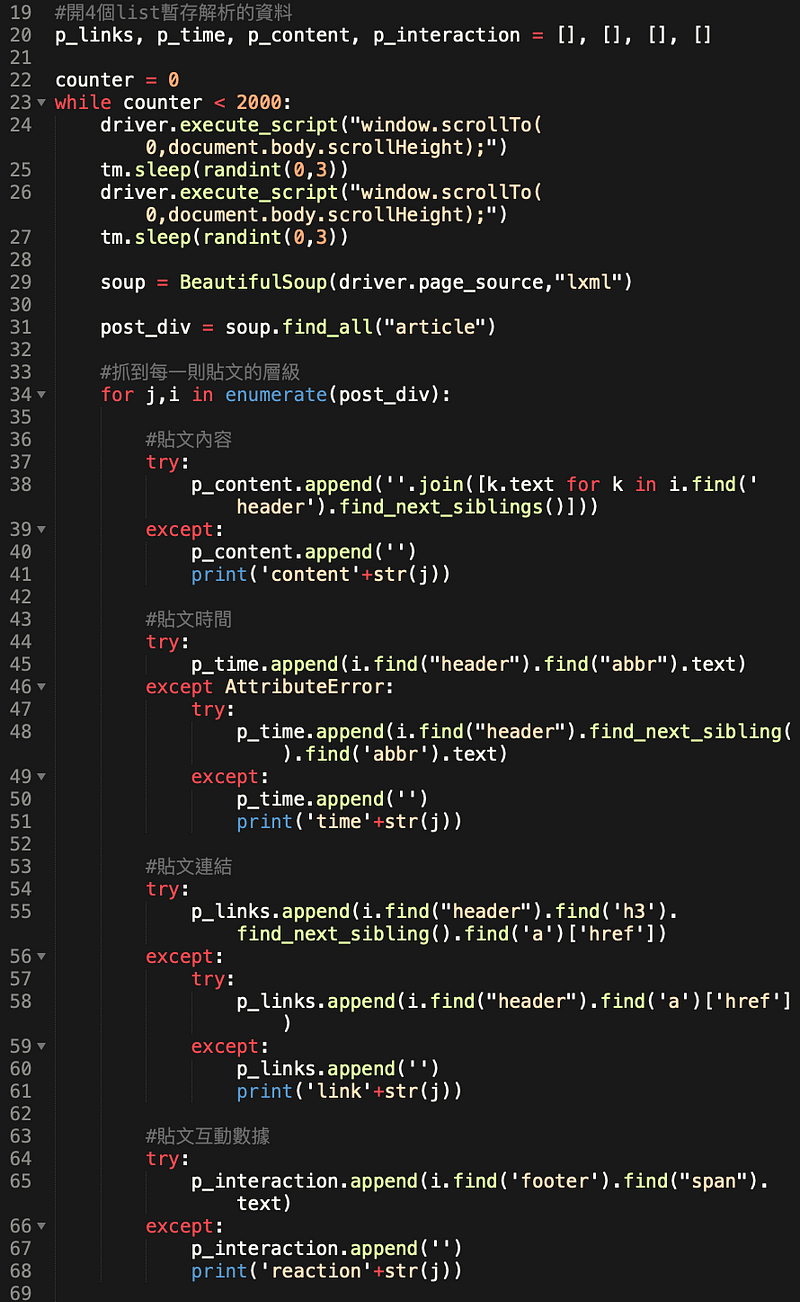
while迴圈就是讓它一直執行,我是大概估算一個數量(結果太多)。原本找到的案例是去判斷最後一則貼文的時間,很精準。但是我後來改抓手機版網頁,取到的日期資料是文字,沒時間做轉換,就暴力開下去了。
觸發頁面loading更多貼文,這是參考案例來的code,就是讓瀏覽器執行捲動到最下面,我貪心一點點,捲動頁面兩次再抓資料(中間間隔幾秒,讓資料load完)。
接下來是去看html tag的步驟。比較難抓的是,class name、id都沒什麼識別意義,包的div又很多很雜,所以會有 .find().find().find_next_siblings() 這種兩、三步驟的定位方法。
有另外一個問題是,不是所有貼文類型都是一樣的html寫法,像是更新大頭貼照、直播,樣態好像就不一樣。因為趕著抓完資料,所以例外控制寫得很粗魯……
後來發現其實用手機版FB比較適合的原因是,預設loading的東西比較少(例如影片不會自動播、直播不能看)載入速度比較快是優點,做起來比桌機版的穩定(只是貼文時間沒有utc-time可取,得存純文字)。
code範例:Python 爬蟲解析:以爬取臉書社團為案例,使用 Selenium 來進行網頁模擬爬蟲
本篇全部的code:
先說為什麼不用facebook graph api抓取?因為現在連公開內容抓取也需要送審應用程式(上圖),一直還沒搞懂/去走一遍流程(抓取自己粉絲頁的數據從2017年開始每天跑都還活著,也多了點偷懶的理由…)
引入套件
在一開始提過了,這次的重點是前三項。selenium、webdriver、BeautifulSoup。
selenium的設定
driver這個地方,在開始前需要去下載一個真的webdriver回來,並且要跟目前使用的瀏覽器是相同版本,例如,你要模擬Chrome的使用狀況,就要找Chrome相同版本。
Chrome Webdriver下載:上網Google吧。我下載後放在專案的資料夾裡,以指定路徑的方式打開,加到環境變數也是一種方法。
如果要把程式部署到雲端主機就有另外的設定方法,我有部署到Heroku過,也是東找範例西找解方做出來,下次再整理出來。
這段執行完,瀏覽器就會打開了,如果要手動以帳號密碼登入也是可以的。這裡輸入的是m.facebook.com的版本喔!
抓取內容
while迴圈就是讓它一直執行,我是大概估算一個數量(結果太多)。原本找到的案例是去判斷最後一則貼文的時間,很精準。但是我後來改抓手機版網頁,取到的日期資料是文字,沒時間做轉換,就暴力開下去了。
觸發頁面loading更多貼文,這是參考案例來的code,就是讓瀏覽器執行捲動到最下面,我貪心一點點,捲動頁面兩次再抓資料(中間間隔幾秒,讓資料load完)。
接下來是去看html tag的步驟。比較難抓的是,class name、id都沒什麼識別意義,包的div又很多很雜,所以會有 .find().find().find_next_siblings() 這種兩、三步驟的定位方法。
有另外一個問題是,不是所有貼文類型都是一樣的html寫法,像是更新大頭貼照、直播,樣態好像就不一樣。因為趕著抓完資料,所以例外控制寫得很粗魯……
存檔
把資料化成DataFrame再吐出csv。最初其實怕抓到一半session斷掉,所以依據counter數分段存檔。但其實這種抓取的缺點是:一定得從最新的貼文開始跑,所以現在看來,中間有存沒存其實都沒差,session沒斷掉才是重點。後來發現其實用手機版FB比較適合的原因是,預設loading的東西比較少(例如影片不會自動播、直播不能看)載入速度比較快是優點,做起來比桌機版的穩定(只是貼文時間沒有utc-time可取,得存純文字)。
code範例:Python 爬蟲解析:以爬取臉書社團為案例,使用 Selenium 來進行網頁模擬爬蟲
本篇全部的code:
留言